
Introducción
Hola, quiero darte la Bienvenida a este nuevo Post, sobre las Herramientas y Técnicas Estadísticas utilizadas en la Data Mining o Minería de Datos y el Business Intelligence o Inteligencia Empresarial, vamos a profundizar un poco sobre cada una de estas tecnicas, aprendiendo los conceptos fundametales, con algunos ejemplos en Python sobre cada una, tratando de forma básica pero entendible, para sacar el maximo provecho de tus datos.
Tabla de contenidos
ToggleEspero que este artículo sea te sea útil para conocer más sobre Informacion y el manejo de los datos, asi como las herramientas mas utilizadas dentro de la Estadística. Gracias por visitar mi blog y no dude en dejar sus comentarios, preguntas y lo mas importante !no olvides suscriberte y seguirme en las Redes Sociales.
Herramientas Estadísticas
Las herramientas estadísticas son un conjunto de técnicas y métodos utilizados para analizar y entender datos. Estos métodos nos permiten obtener información relevante sobre un conjunto de datos, haciendo inferencias y sacando conclusiones sobre el mismo.
En este artículo, vamos a profundizar en algunas de las herramientas más comunes y fundamentales de estadísticas, así como en sus aplicaciones y ejemplos de cálculo en Python.
La estadistica resulta de mucha en para la minería de datos, ya que es una disciplina interdisciplinaria que combina conocimientos de estadística, ciencia de datos, aprendizaje automático, entre otros para extraer información útil de grandes conjuntos de datos. El Business Intelligence (BI) es un conjunto de técnicas y herramientas que se utilizan para recopilar, integrar, analizar y presentar datos con el objetivo de mejorar la toma de decisiones en una empresa o organización.
Entre las herramientas y técnicas estadísticas más comunes utilizadas en la minería de datos y el BI se encuentran:
Análisis de componentes principales (PCA): Es una técnica utilizada para reducir la dimensionalidad de un conjunto de datos mediante la identificación de las principales características o componentes de los datos.
Análisis discriminante: Es una técnica estadística utilizada para analizar y clasificar datos mediante la identificación de patrones en los datos que permiten diferenciar entre diferentes grupos o categorías.
Agrupamiento (clustering): Es una técnica utilizada para agrupar datos similares en conjuntos o «clusters». El agrupamiento puede ser utilizado para descubrir patrones y estructuras ocultas en los datos.
Regresión: Es una técnica estadística utilizada para analizar la relación entre una variable independiente y una o más variables dependientes.
Análisis de supervivencia: Es una técnica estadística utilizada para analizar datos relacionados con eventos de tiempo de vida, como el tiempo de falla de un producto o el tiempo de supervivencia de pacientes con una enfermedad.
Para implementar estas técnicas, hay muchas librerías en python que podemos utilizar, como sklearn, pandas, matplotlib, seaborn, entre otros. Cada una de estas librerías tiene sus funciones y herramientas específicas para realizar los diferentes análisis, aunque veremos que existe una grantidad de software y herramientas, hablaremos de algunos, pero los ejemplos seran realizados con Python.
Las herramientas estadísticas

Las herramientas estadísticas: son un conjunto de técnicas y metodologías que se utilizan para recopilar, analizar y presentar datos. Estas herramientas son esenciales en una variedad de campos, como la investigación científica, la toma de decisiones empresariales y la planificación gubernamental. A continuación se describen algunas de las características, ventajas y desventajas de las herramientas estadísticas, así como algunos software populares utilizados para su aplicación.
Características de las herramientas estadísticas:
- Permiten recopilar y organizar datos de manera eficiente
- Permiten analizar y visualizar los datos de manera clara y concisa
- Permiten sacar conclusiones y hacer predicciones a partir de los datos
- Permiten la toma de decisiones informadas en base a los datos
Ventajas de las herramientas estadísticas:
- Son una forma eficaz de recopilar y organizar grandes cantidades de datos
- Permiten identificar patrones y tendencias en los datos
- Permiten realizar pruebas estadísticas para determinar la significación de los hallazgos
- Permiten hacer predicciones y tomar decisiones informadas en base a los datos
Desventajas de las herramientas estadísticas:
- Pueden ser complejas y requieren un alto nivel de conocimiento para su aplicación
- Pueden ser costosas, tanto en términos de tiempo como de dinero
- La calidad de las conclusiones obtenidas dependerá de la calidad y cantidad de los datos disponibles
- Los datos pueden ser sesgados o incompletos lo que puede afectar la precisión de las conclusiones
Algunos software utilizados en la aplicación de herramientas estadísticas incluyen:
- R: Es un software de código abierto muy popular en el campo de la estadística y la investigación científica. R tiene una gran variedad de paquetes para el análisis estadístico y la visualización de datos.
- Python: es un lenguaje de programación de código abierto y ampliamente utilizado en una variedad de campos, incluyendo la estadística. Existen varias librerías de Python, como NumPy, Pandas y Matplotlib, que proporcionan una gran cantidad de herramientas estadísticas.
- Excel: Es un software ampliamente utilizado para el análisis y la visualización de datos, es especialmente útil para trabajar con conjuntos de datos pequeños y medianos.
- SAS: Es un software propietario que se utiliza ampliamente en el campo de la investigación y el análisis de datos en el ámbito empresarial.
- SPSS: Es un software propietario que se utiliza ampliamente en el campo de la investigación social y psicológica.
- STATA: es un software estadístico popular para el análisis de datos económico y social. Es ampliamente utilizado en investigaciones universitarias y empresas.
- Minitab: es un software estadístico que ofrece una interfaz fácil de usar y un gran número de funciones para el análisis estadístico. Es popular en las industrias de la fabricación y la calidad.
- MATLAB: es un software de cálculo científico y técnico que tiene un gran conjunto de herramientas estadísticas. Es ampliamente utilizado en la investigación científica y la ingeniería.
2.1 Definición y Ejemplo de Cálculo de parámetros estadísticos
El cálculo de parámetros estadísticos es una técnica esencial en el análisis de datos que permite obtener información útil sobre las características de una población o un conjunto de datos. Los parámetros estadísticos incluyen medidas como la media, la desviación estándar, la mediana, la moda, y los percentiles. A continuación se describen algunas de las características, ventajas y desventajas de los parámetros estadísticos, así como algunos software utilizados para su cálculo.
Características de los parámetros estadísticos:
- Son medidas resumen de un conjunto de datos
- Permiten obtener información valiosa sobre las características de una población o un conjunto de datos
- Permiten hacer comparaciones y realizar pruebas estadísticas
- Se pueden calcular utilizando software estadístico o con formulas matemáticas.
Ventajas de los parámetros estadísticos:
- Proporcionan una visión general de las características de un conjunto de datos
- Permiten comparar y contrastar conjuntos de datos
- Son útiles para realizar pruebas estadísticas y determinar la significancia de los hallazgos.
- Son fáciles de calcular y entender.
Desventajas de los parámetros estadísticos:
- No proporcionan información detallada sobre cada punto de datos.
- Pueden ser afectados por valores atípicos o outliers
- no proporcionan información sobre distribución de datos.
- Pueden ser afectados por la escala y el rango de los datos
Los parámetros estadísticos son medidas que se utilizan para resumir y describir un conjunto de datos. Algunos ejemplos de parámetros estadísticos son la media, la mediana, el desvío estándar, etc.
La media: es una medida de tendencia central que se calcula sumando todos los valores de un conjunto de datos y dividiéndolos entre el número de elementos. Por ejemplo, si tenemos un conjunto de datos compuesto por los valores
El código Python para calcular la media de un conjunto de datos es el siguiente:

Aqui podemos ver que el resultado es la Suma de 949, y la Media de esos valores es 31.6133. Suponiendo que estos datos sean edades.
2.2 Medidas de Tendencia Central (Medias, varianzas, correlaciones, etc.)
Las medidas de tendencia central son aquellas que nos permiten conocer el «centro» de un conjunto de datos. Algunas de las medidas más comunes son la media que ya vimos en el ejemplo anterior y la mediana.
La mediana: es el valor que se encuentra en el centro de un conjunto de datos ordenados. Si el número de elementos es par, la mediana se calcula como la media de los dos valores centrales. Por ejemplo, si tenemos un conjunto de datos compuesto por los valores [1, 2, 3, 4, 5], la mediana sería 3.
El código Python para calcular la mediana de un conjunto de datos es el siguiente:

Aqui podemos ver que el resultado es la Suma de 949, y la Mediana de esos valores es 34, que esta practica a la mitad de los datos a derecha y la izquierda.
La varianza: es otra medida que se utiliza para describir la dispersión de un conjunto de datos. Se calcula como el promedio de la suma de las diferencias cuadradas entre cada valor y la media.
El código Python para calcular la varianza de un conjunto de datos es el siguiente:
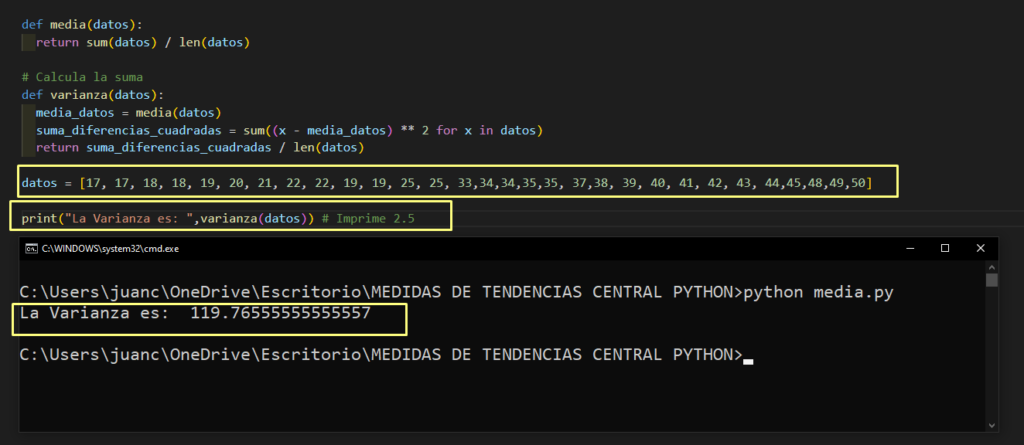
Aqui podemos ver que el resultado de la Varianza es de esos valores es 119.765.
La correlación: es una medida que se utiliza para evaluar la relación entre dos conjuntos de datos. Existen diferentes tipos de correlación, como la correlación de Pearson, que mide la relación lineal entre dos variables, y la correlación de Spearman, que mide la relación monótona entre dos variables.
El código Python para calcular la correlación de Pearson entre dos conjuntos de datos es el siguiente:

2.3 Definición y Ejemplo de Técnicas bayesianas
Las técnicas bayesianas: son un enfoque probabilístico para el análisis de datos que se basa en el concepto de la distribución de probabilidad. Estas técnicas se utilizan para estimar parámetros de interés a partir de datos observados y para hacer predicciones sobre futuros eventos.
Por ejemplo, supongamos que queremos estimar la probabilidad de que una moneda sea justa (es decir, que tenga una probabilidad igual de salir cara o cruz). Podemos utilizar técnicas bayesianas para calcular la distribución de probabilidad de la proporción de veces que saldrá cara, a partir de un conjunto de datos que contiene el número de veces que ha salido cara y cruz al lanzar la moneda un número determinado de veces.
El código Python para estimar la distribución de probabilidad de la proporción de veces que saldrá cara utilizando técnicas bayesianas es el siguiente:

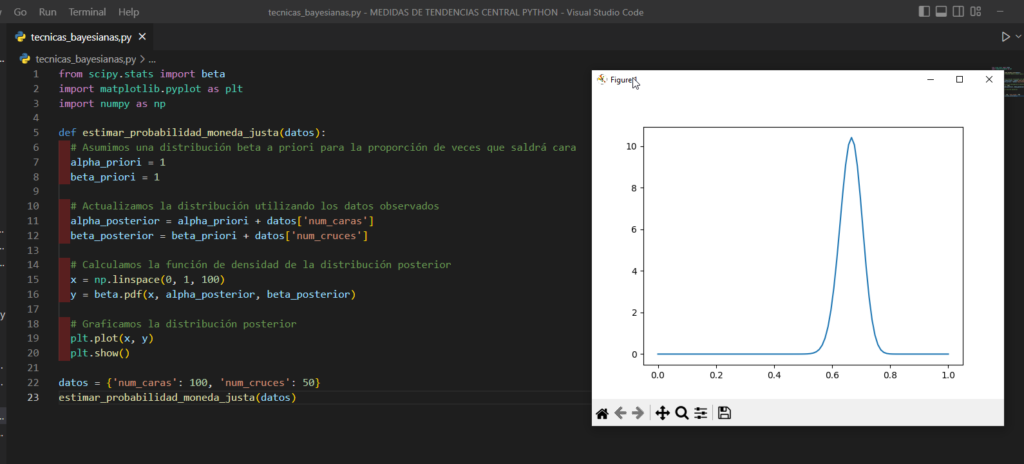
.
2.4 Definición y Ejemplo de Prueba de hipótesis
Las pruebas de hipótesis: son herramientas estadísticas que se utilizan para evaluar si una afirmación o hipótesis es cierta o no. Estas pruebas se basan en la comparación de una medida de tendencia central (como la media) entre dos conjuntos de datos, y se utilizan para determinar si existe una diferencia significativa entre ambos conjuntos.
Por ejemplo, supongamos que queremos evaluar si existe una diferencia significativa en el tiempo de respuesta de dos grupos de usuarios en una aplicación web. Podemos utilizar una prueba de hipótesis para comparar la media del tiempo de respuesta entre ambos grupos y determinar si existe una diferencia significativa entre ellos.
El código Python para realizar una prueba de hipótesis para comparar la media de dos conjuntos de datos utilizando el test de Student es el siguiente:

.
2.5 Definición y Ejemplo de Técnicas de regresión lineal
La regresión lineal: es una técnica estadística que se utiliza para modelar la relación entre dos variables. Se basa en la idea de que existe una relación lineal entre las variables, de forma que al aumentar una de ellas, la otra también aumenta (o disminuye) de forma proporcional.
Por ejemplo, supongamos que queremos modelar la relación entre la edad y el salario de un conjunto de trabajadores. Podemos utilizar una regresión lineal para encontrar la ecuación de la recta que mejor se ajusta a los datos y predecir el salario de un trabajador dado su edad.
El código Python para realizar una regresión lineal utilizando el módulo scikit-learn es el siguiente:

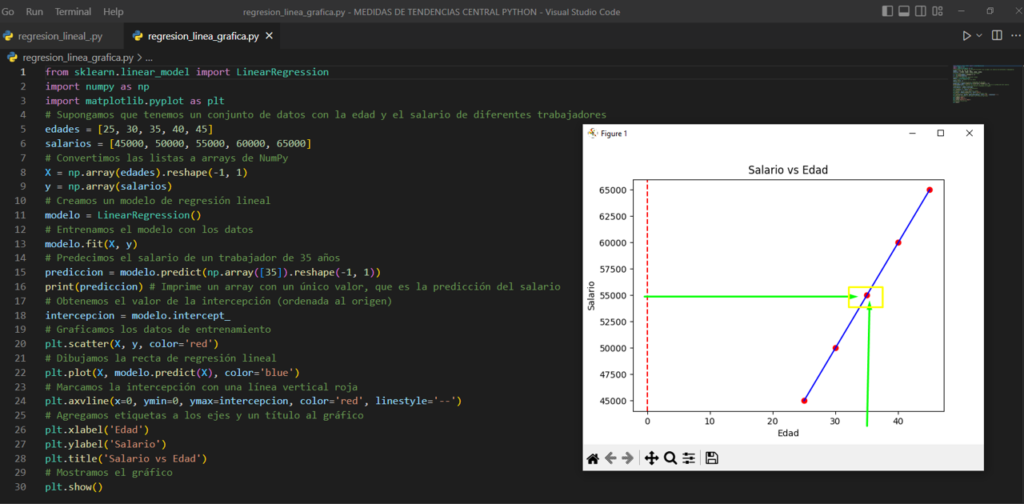
.
2.6 Definición y Ejemplo de Análisis multivariante
El análisis multivariante: es una técnica estadística que se utiliza para analizar el efecto de múltiples variables sobre una variable de interés. Algunas de las herramientas más comunes utilizadas en el análisis multivariante son el análisis de varianza (ANOVA), la regresión múltiple y el análisis de componentes principales (PCA).
Por ejemplo, supongamos que queremos evaluar el efecto del tipo de alimentación, la raza y el sexo en el peso de un conjunto de perros. Podemos utilizar un análisis de varianza para evaluar si existen diferencias significativas en el peso entre los diferentes grupos de perros definidos por las variables de alimentación, raza y sexo.
El código Python para realizar un análisis de varianza utilizando el módulo statsmodels es el siguiente:


.
2.7 Análisis Cluster (Agrupación de datos para efectuar la segmentación)
El análisis de cluster: es una técnica de análisis de datos que se utiliza para agrupar observaciones en conjuntos o «clusters» de forma que las observaciones de un mismo cluster sean similares entre sí y diferentes a las observaciones de otros clusters. Esta técnica se utiliza a menudo para la segmentación de clientes en el marketing o para la agrupación de textos en tareas de procesamiento de lenguaje natural.
Por ejemplo, supongamos que queremos agrupar un conjunto de documentos en diferentes temas. Podemos utilizar el análisis de cluster para agrupar los documentos en diferentes clusters en función de su similitud en términos de palabras clave o frases comunes.
El código Python para realizar un análisis de cluster utilizando el algoritmo K-Means y el módulo scikit-learn es el siguiente:
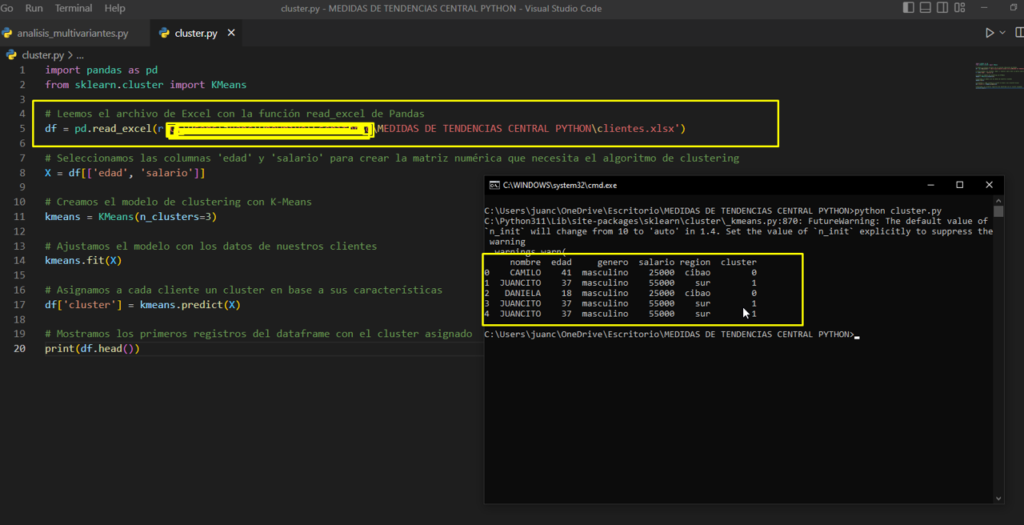

2.8 Otras Herramientas Estadísticas y cálculos
Hay muchas otras herramientas y cálculos estadísticos que no hemos mencionado aquí, como el análisis de varianza múltiple (MANOVA), el análisis factorial, el análisis de covarianza (ANCOVA), el análisis de supervivencia, entre muchos otros. Cada una de estas herramientas tiene sus propias aplicaciones y utilizaciones en diferentes áreas de estudio.
El análisis de varianza múltiple (MANOVA): es una técnica estadística utilizada para evaluar si existen diferencias significativas entre dos o más grupos en más de una variable al mismo tiempo. Se utiliza a menudo en el análisis de datos experimentales, en el que se controlan o manipulan ciertas variables para evaluar su efecto sobre otras variables. A diferencia de un análisis de varianza (ANOVA) unidimensional, donde se evalúa la diferencia en una sola variable, el MANOVA permite evaluar si hay diferencias en varias variables al mismo tiempo.
El MANOVA utiliza un enfoque estadístico basado en la matemática lineal para evaluar la relación entre las variables independientes y las variables dependientes. La hipótesis nula en un MANOVA es que no hay diferencia significativa en las variables dependientes entre los grupos definidos por las variables independientes.
Una de las ventajas del MANOVA es que permite analizar varias variables dependientes simultáneamente, lo que aumenta la capacidad de detectar diferencias significativas. Sin embargo, también tiene algunas limitaciones. Por ejemplo, el MANOVA requiere que las variables dependientes sean continuas y estén relacionadas de manera lineal. Además, al comparar varias variables dependientes al mismo tiempo, el MANOVA puede generar resultados poco claros y difíciles de interpretar. Por lo tanto, es importante tener cuidado al utilizar esta técnica y asegurarse de que se cumplan los supuestos necesarios.
Un ejemplo de código para realizar un MANOVA con dos variables independientes y una variable dependiente sería el siguiente:
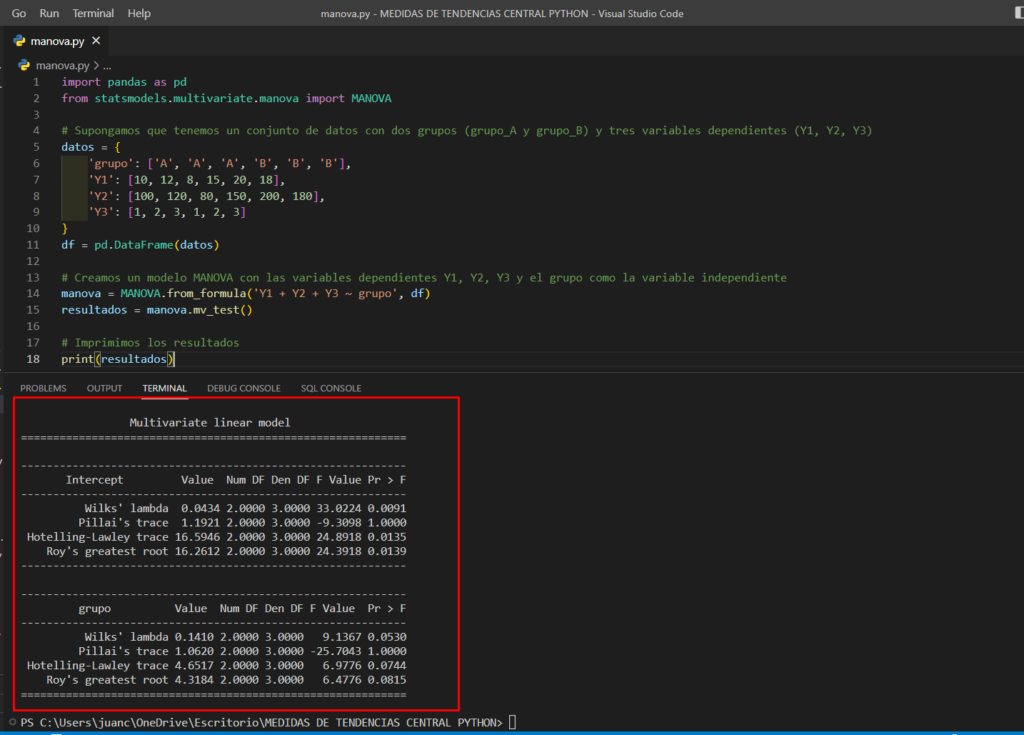
En este ejemplo, tenemos un conjunto de datos con dos grupos (grupo_A y grupo_B) y tres variables dependientes (Y1, Y2, Y3). Utilizamos la librería statsmodels para realizar un análisis MANOVA con el grupo como la variable independiente y las variables dependientes Y1, Y2, Y3. El resultado del análisis se imprime en pantalla, incluyendo la significancia del test y los valores de los estadísticos Wilks’ lambda, Hotelling-Lawley Trace y Roy’s Largest Root.
El análisis factorial: es una técnica estadística utilizada para reducir la dimensionalidad de un conjunto de datos y extraer las características o factores más importantes que explican la mayor parte de la variabilidad en los datos. Se utiliza a menudo en la investigación de mercado y en el análisis de encuestas.
Para el análisis factorial en Python, se puede utilizar el paquete sklearn. Un ejemplo de código para realizar un análisis factorial con dos factores sería el siguiente:

El objetivo principal del análisis factorial es encontrar los factores o dimensiones subyacentes que explican la mayor cantidad de varianza en los datos. Esto se logra mediante la rotación de los factores, que es un proceso mediante el cual se mueven las variables originales en un espacio multidimensional para obtener una mejor interpretación.
Existen dos tipos principales de análisis factorial: el análisis factorial confirmatorio y el análisis factorial exploratorio. El análisis factorial confirmatorio se utiliza cuando ya se tiene una teoría sobre la estructura de los datos, mientras que el análisis factorial exploratorio se utiliza cuando se desconoce la estructura subyacente.
En el análisis factorial confirmatorio, se asume una estructura específica para los datos y se utiliza para evaluar si los datos encajan en esa estructura. Se utilizan métodos estadísticos para evaluar la bondad de ajuste de los datos a la estructura especificada y los cálculos de las cargas factoriales que indican cuan bien cada variable se relaciona con cada factor.
En el análisis factorial exploratorio, se busca explorar los datos sin ninguna suposición previa. Se utilizan métodos estadísticos para identificar patrones en los datos y determinar la estructura subyacente. La metodología de esta técnica es subjetiva y no hay una respuesta única que explique todo el conjunto de variables.
La interpretación de los resultados del análisis factorial puede ser compleja, especialmente cuando se utiliza el análisis factorial exploratorio. Es importante tener en cuenta que los factores identificados no necesariamente son causales, sino que pueden simplemente reflejar patrones o tendencias en los datos. Además, es importante evaluar la validez de los factores encontrados mediante la verificación empírica.
El análisis de covarianza (ANCOVA):es una técnica estadística que se utiliza para comparar dos o más grupos en relación con una variable dependiente continuamente medida, teniendo en cuenta la influencia de una o varias variables covariadas. La idea detrás de esta técnica es controlar la influencia de las variables covariadas, para poder hacer comparaciones más precisas entre los grupos en relación con la variable dependiente.
Un ejemplo de cuando se podría utilizar ANCOVA es en un estudio en el que se quiere comparar el rendimiento académico de dos grupos de estudiantes: uno que recibió una intervención educativa específica y otro que no la recibió. La variable dependiente sería el rendimiento académico, medido por la puntuación en un examen específico. La variable covariada podría ser el nivel de habilidad matemática previa de los estudiantes, ya que esto podría afectar significativamente el rendimiento académico. Al controlar la influencia de este factor, el ANCOVA permite comparar el rendimiento académico de los dos grupos de estudiantes con mayor precisión.
En Python, podemos realizar ANCOVA utilizando la librería statsmodels. A continuación, se muestra un ejemplo de cómo se podría llevar a cabo un ANCOVA para comparar el rendimiento académico de dos grupos de estudiantes, teniendo en cuenta el nivel de habilidad matemática previa de los estudiantes:
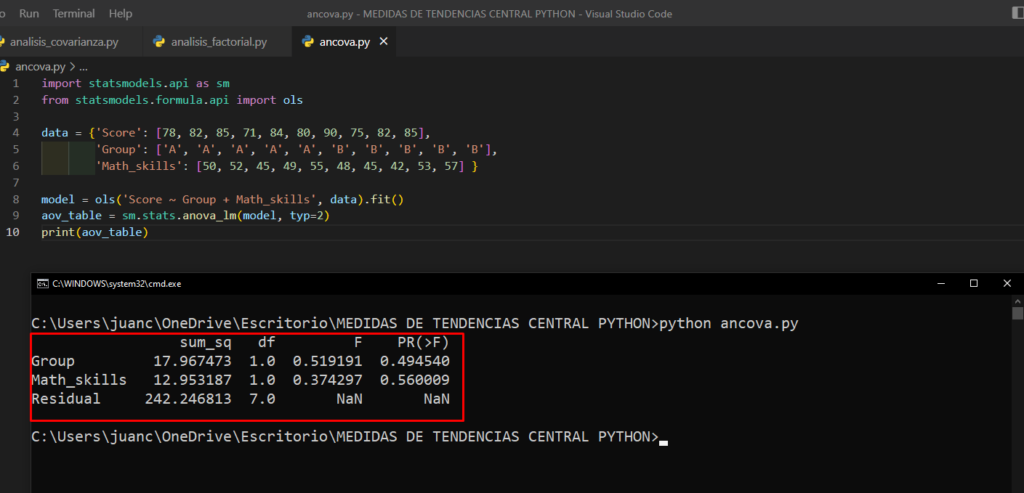
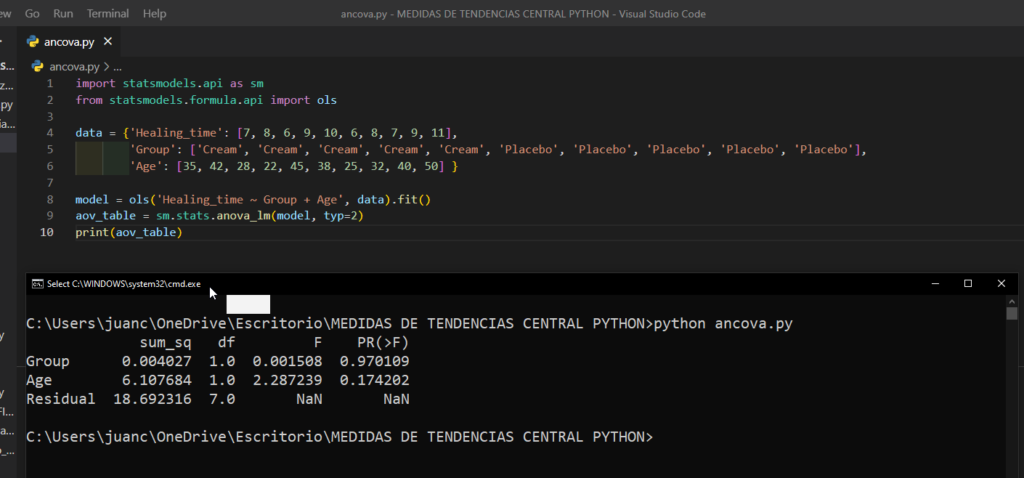
En el ejemplo anterior se esta utilizando statsmodels para calcular el ANCOVA y se esta utilizando Healing_time como variable dependiente, Group como variable independiente y Age como variable covariable. El resultado de aov_table te dará las estadisticas necesarias para evaluar si hay diferencias significativas entre los grupos y también si la variable covariable es importante en el modelo.
2.9 Conclusiones Generales
En este artículo hemos visto algunas de las herramientas y técnicas más comunes utilizadas en la estadística, como la del cálculo de parámetros estadísticos, las medidas de tendencia central, las técnicas bayesianas, las pruebas de hipótesis, la regresión lineal, el análisis multivariante, el análisis de cluster y otras herramientas estadísticas.
Vimos las definiciones de la estadística, que es una herramienta valiosa que permite obtener información valiosa de los datos, en este contexto hay varias herramientas y técnicas comunes que se utilizan para analizar y entender los datos.
Entre las herramientas más comunes se encuentran las técnicas de cálculo de parámetros estadísticos, como la media aritmética, la desviación estándar y la varianza, estas herramientas permiten tener una idea de cómo se distribuyen los datos y cómo varían los valores de una variable en particular.
Las medidas de tendencia central, como la mediana y el percentil, son otras herramientas útiles para entender cómo se distribuyen los datos. Permiten evaluar cual es el valor que se encuentra en el centro de un conjunto de datos y que refleja la tendencia.
Las técnicas bayesianas son otra herramienta importante en la estadística, ya que permiten modelar la incertidumbre y utilizar la información previa para mejorar las predicciones.
En la estadística también se realizan muchas pruebas de hipótesis, especialmente para determinar si existen diferencias significativas entre grupos o para evaluar la bondad de ajuste de un modelo. Entre las pruebas de hipótesis más comunes se incluyen el t-test, ANOVA, chi-cuadrado y la prueba de proporciones.
La regresión lineal es otra herramienta comúnmente utilizada en la estadística, ya que permite modelar la relación entre dos o más variables continuas. Es una herramienta muy útil para predecir el valor de una variable a partir de otra variable.
El análisis multivariante, como el análisis de componentes principales (PCA) y el análisis de varianza múltiple (MANOVA), son técnicas que permiten analizar la relación entre varias variables. Estas herramientas son especialmente útiles para identificar patrones en los datos y para hacer inferencias sobre la relación entre las variables.
El análisis de cluster es una herramienta estadística utilizada para agrupar elementos similares en diferentes grupos o clusters, y se utiliza a menudo para la segmentación de clientes o para la identificación de patrones en grandes conjuntos de datos.
Cada una de estas herramientas tiene sus propias aplicaciones y utilizaciones en diferentes áreas de estudio y es importante comprender cómo funcionan y cuándo utilizarlas para poder realizar análisis de datos de manera efectiva.
Es importante tener en cuenta que estas herramientas y técnicas son solo una pequeña parte de lo que abarca la estadística y que existen muchas otras técnicas y conceptos que no hemos mencionado aquí. A medida que se recopila más información y se desarrollan nuevas herramientas y tecnologías, la estadística continúa siendo una herramienta esencial para entender y tomar decisiones en base a los datos.
3.0 -Libros Recomendados:
A continuacion, te recomiendo algunos libros, de los cuales estuve investigando en varios sitios, foros, y videos, y son de los mas importantes, porque proporcionan una introducción o una guía práctica para el análisis de datos y el uso de herramientas estadísticas. Estos libros pueden ayudar a los lectores a comprender mejor los conceptos fundamentales y las técnicas utilizadas en el análisis de datos, y a adquirir las habilidades necesarias para aplicar estas técnicas en su trabajo o investigaciones.
En mi caso particular, peudo decirte que para mi tienen una la relevancia muy alta, son valiosos porque el análisis de datos es esencial en una variedad de campos, como la investigación científica, la toma de decisiones empresariales, la economía, la salud, nos permite a las organizaciones y a las personas tomar decisiones basadas en datos o evidencias y en este campo cada vez más se requiere de profesionales que sepan manejar, analizar, y sacar conclusiones relevantes de grandes volúmenes de datos, y sin una ayuda de otros escritores y profesionales del campo que han plasmado sus tecnicas para que otros puedan seguri adelante.
Aquí te menciono algunos ejemplos en Español:
«Aprendizaje Estadístico» de Luis Torgo: este libro ofrece una introducción a los conceptos básicos de aprendizaje automático y es utilizado en cursos universitarios.
«Estadística para Ciencia de Datos» de Rafael A. Olvera-Cravioto: este libro proporciona una introducción a los conceptos básicos de estadística y cómo aplicarlos en el análisis de datos.
«Análisis de datos con R y Python» de Javier Muñoz y Leopoldo Sánchez: este libro ofrece una guía práctica para el análisis de datos utilizando R y Python y se enfoca en la aplicación de técnicas estadísticas.
«Python para Análisis de Datos» de Wes McKinney: este libro es una guía para el análisis de datos utilizando Python y se ha convertido en un recurso popular para aquellos que buscan aprender sobre el tema.
«Big Data y Business Intelligence» de Carlos Lara: Este libro es una guía para el análisis de grandes volúmenes de datos y su utilización en la toma de decisiones de negocio.
Otros libros relacionados con las herramientas estadísticas en English:
«An Introduction to Statistical Learning» de Gareth James, Daniela Witten, Trevor Hastie y Robert Tibshirani: Este libro ofrece una introducción a los conceptos básicos de aprendizaje automático y es ampliamente utilizado en cursos universitarios.
«The Elements of Statistical Learning» de Trevor Hastie, Robert Tibshirani y Jerome Friedman: Este libro es considerado como una referencia en el campo del aprendizaje automático y es ampliamente utilizado en la industria.
«Applied Predictive Modeling» de Max Kuhn y Kjell Johnson: Este libro es una guía práctica para el modelado predictivo y se centra en el uso de modelos para la toma de decisiones en la industria.
«R for Data Science» de Hadley Wickham y Garrett Grolemund: Este libro es una guía para el análisis de datos en R y se ha convertido en una referencia popular para los usuarios de R.
«Data Science from Scratch» de Joel Grus: Este libro proporciona una introducción a los conceptos básicos de ciencia de datos y es un recurso popular para aquellos que buscan aprender sobre el tema.
3.1 -Certificaciones Recomendados:
Te recomiendo algunas certificaciones, estas son importantes porque proporcionan una forma de demostrar que un individuo tiene un nivel de conocimiento y habilidad en un área específica. Las certificaciones pueden ser especialmente valiosas en el campo de la estadística y el análisis de datos, ya que estos campos son altamente técnicos y requieren un alto nivel de conocimiento. Una certificación también puede ayudar a un individuo a destacarse en el mercado laboral y a mejorar sus oportunidades de carrera.
Existen varias Certificaciones, las hay en diferentes niveles y áreas, pero aquí te menciono algunas que son ampliamente reconocidas y consideradas relevantes en el campo de la estadística y el análisis de datos:
- Certificado en el lenguaje R de la Fundación R.
- Certificado de Data Scientist de Cloudera.
- Certificado de especialista en análisis de datos de Microsoft.
- Certificado de especialista en minería de datos de SAS.
- Certificado de especialista en análisis estadístico de IBM.
Sigueme en mis Redes Sociales
Si te gusta el contenido que estoy compartiendo, no lo pienses mas y suscríbete al Blog, y al canal de Youtube para que recibas las notificaciones cada vez que publicamos nuevos temas, No Olvides Compartirlo me ayudas un Monton..
¡Gracias por leer! Esperamos que encuentres este post útil y te animamos a dejar tus comentarios y preguntas a continuación.