
SQL Server Comados, Operaciones Básicas y CRUD
En un Post y video anterior vimos algunas informaciones de SQL Server, y hablamos que es un motor de Base de Datos Gratuito en su versión Express y Developer, que permite almacenar información ordenada y estructurada de manera tal que pueda ser consultada rápidamente. Puede ser utilizado para Crear las bases de datos de varios Sitios Web, Aplicaciones para dispositivos móviles, aplicaciones de Escritorio o bien para almacenar datos de un Videojuego o cualquier aplicación o software empresarial como inventarios, facturas, contabilidad, etc.
Tabla de contenidos
ToggleRealizamos unos Ejercicios Básicos, y hoy vamos a seguir aprendiendo algunos conceptos básicos como son las relaciones, un ejemplo básico de Normalización, y como podemos crear 3 tablas y hacer una relación entre ellas por medio de un campo en común, y veremos como responder preguntas que me pueden hacer y que puedo contestar con SQL Server, y usos de Funciones como Count, Funciones de Fecha como DATEDIFF, así como crear unas consultas combinadas con Join, y creación de una vista.
Recordando lo mencionado anteriormete, hechemos un vistazo a estos conceptos nuevamente:
Una base de datos es un conjunto de información organizada de manera sistemática y estructurada de manera que permiten una rápida y eficiente búsqueda, acceso y actualización de la información. Es importante en la actualidad porque nos permite almacenar y gestionar grandes cantidades de datos de manera eficiente y segura, y nos ofrece la posibilidad de realizar análisis y obtener informes de manera rápida y sencilla para presentarla en informes, reportes y dashboard a la gerencia o administracion o inversionistas para la toma de desiciones de forma inteligente e informada.
Es importante aprender a manejar y dominar las bases de datos porque son una herramienta fundamental en la mayoría de las empresas y organizaciones, ya que nos permiten llevar un control preciso y detallado de los datos y la información que manejamos. Además, el conocimiento y manejo de bases de datos es una habilidad valiosa en el mundo laboral, ya que muchas empresas requieren a sus empleados que tengan conocimientos en este ámbito.
En el desarrollo de aplicaciones: Las bases de datos se utilizan para almacenar y gestionar los datos que necesita la aplicación para funcionar. Por ejemplo, en una aplicación web de comercio electrónico, la base de datos podría almacenar información sobre los productos que se venden, los clientes que realizan compras, y las compras realizadas. En este caso, la base de datos se está utilizando para almacenar y gestionar datos que son necesarios para el funcionamiento de la aplicación.
Por otro lado, las bases de datos orientadas al análisis de datos: Se utilizan para almacenar y gestionar grandes cantidades de datos que se utilizan para realizar análisis y obtener información valiosa para la toma de decisiones. Estas bases de datos se utilizan en áreas como el data mining, el big data y el análisis de negocios. En este caso, la base de datos se está utilizando para almacenar y gestionar grandes cantidades de datos que se utilizan para obtener información valiosa y útil para la empresa u organización.
SQL (Structured Query Language) es el lenguaje de consulta estandarizado que se utiliza para acceder y gestionar bases de datos relacionales. Es un lenguaje de alto nivel que nos permite realizar operaciones como seleccionar, insertar, actualizar y eliminar datos en una base de datos.
Existen dos tipos principales de bases de datos: las relacionales y las no relacionales.
Las bases de datos relacionales: Se basan en un modelo de datos en el que se utilizan tablas para almacenar los datos y se establecen relaciones entre ellas mediante claves foráneas. Esto permite una mayor flexibilidad y normalización de los datos, lo que hace que sean ideales para aplicaciones que necesitan almacenar y gestionar grandes cantidades de información estructurada. El lenguaje de consulta más comúnmente utilizado con bases de datos relacionales es el Structured Query Language (SQL).
Las bases de datos no relacionales: Se basan en un modelo de datos más flexible que no requiere la estructuración previa de los datos. Esto las hace ideales para aplicaciones que necesitan almacenar y procesar grandes cantidades de datos no estructurados o semi-estructurados, como puede ser el caso de las aplicaciones de big data o el análisis de datos. Algunos ejemplos de bases de datos no relacionales son MongoDB, Cassandra y Redis.
Las bases de datos relacionales utilizan lenguajes de definición de datos (DDL) para crear y modificar la estructura de la base de datos, como tablas y relaciones. Los lenguajes de consulta de datos (DQL) se utilizan para realizar consultas y obtener información de la base de datos. Los lenguajes de manipulación de datos (DML) se utilizan para insertar, actualizar y eliminar datos de la base de datos. Los lenguajes de control de datos (DCL) se utilizan para controlar el acceso a la base de datos y garantizar la integridad de los datos. Los lenguajes de transacción (TCL) se utilizan para gestionar transacciones en la base de datos, que son un conjunto de operaciones que deben completarse de manera atómica (es decir, todas o ninguna).
El modelo de datos relacional es una forma de almacenar y gestionar información en una base de datos. Este modelo se basa en la idea de representar la información en forma de tablas o relaciones, en las que cada fila representa una entidad o un hecho y cada columna representa un atributo o una propiedad de esa entidad o hecho.
Una de las principales ventajas del modelo de datos relacional es su capacidad para representar de manera eficiente y consistente información compleja y relacionada de diferentes ámbitos. Además, este modelo permite establecer relaciones entre tablas y garantizar la integridad de los datos mediante la utilización de claves primarias y claves foráneas.
Un ejemplo típico de aplicación del modelo de datos relacional es una base de datos de clientes de una empresa, en la que se pueden almacenar tablas con información sobre clientes, pedidos, productos y empleados, y establecer relaciones entre ellas para poder obtener información más detallada y compleja.
Una forma especialmente útil de representar las relaciones en una base de datos relacional es mediante el modelo de tipo de nieve y estrella. Este modelo se caracteriza por tener una tabla central que actúa como nodo principal y a la que se relacionan varias tablas secundarias, formando un patrón en forma de estrella. Este modelo es muy útil para representar relaciones de muchos a muchos, ya que permite almacenar la información de manera eficiente y evitar redundancias.
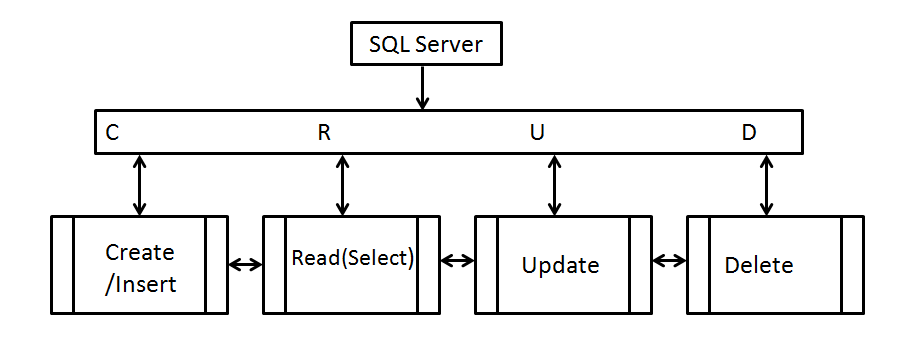
En la Informatica, en la Programacion, o Ciencia Computacion, se utiliza para, crear, leer, actualizar y eliminar estas Operaciones se les llama (CRUD), estas son las cuatro funciones básicas del almacenamiento persistente. A veces se utilizan palabras alternativas al definir las cuatro funciones básicas de CRUD, como recuperar en lugar de leer, modificar en lugar de actualizar o destruir en lugar de eliminar. CRUD también se usa a veces para describir las convenciones de la interfaz de usuario que facilitan la visualización, la búsqueda y el cambio de información; a menudo utilizando formularios e informes basados en computadora.
Las funciones CRUD son las funciones básicas que nos permiten interactuar con una base de datos. «C» significa create, que nos permite crear nuevos registros en la base de datos. «R» significa read, que nos permite leer y obtener información de la base de datos. «U» significa update, que nos permite actualizar registros existentes en la base de datos. «D» significa delete, que nos permite eliminar registros de la base de datos.
El término probablemente fue popularizado por primera vez por James Martin en su libro de 1983 sobre la gestión del entorno de base de datos.
El acrónimo puede extenderse a CRUDL para cubrir la lista de grandes conjuntos de datos que aportan complejidad adicional, como la paginación, cuando los conjuntos de datos son demasiado grandes para guardarlos fácilmente en la memoria «

James Martin
Un ejemplo de CRUD en sistema o formulario seria el que estamos viendo, un formulario en C# con una conexion a SQL Server, a la cual se conecta y se realizan estas operaciones que almacen datos en la tabla contacto que hemos creado en el post anterior, los cuales podemos Insertar, Borrar, Actualizar, y Consultar, etc, desde una aplicacion local o remota.

Aqui como puedes ver tienes un ejemplo ahora desde un Dispositivo Android, donde almacenamos la misma informacion y la enviamos a la Base de Datos en su tabla contacto.

Puede ser implementado en las redes sociales, cada vez que publicas un post, una entrada en tu perfil, cada compartes una foto, un comentario, cuando lo eliminas, lo modificas, eso se guarda en una base de dato, cada vez que subes un video a youtube o tiktok, etc, todo eso es a una base de dato, y el proceso en su mayoria es un CRUD, aunque no en todos la base de datos sea la misma.

Un CRUD puede ser implementado en diferentes entornos, por ejemplouna aplicacion comencial de ventas para registrar los clientes, los productos, los pedidos, las facturas, las entregas, en fin todo el registro de las transacciones de esos clientes.

Conjuntos de comandos DDL, DQL, DML, DCL, TCL:
Ahora pasemos a revisar los diferentes conjuntos de comandos que se utilizan en el modelo de datos relacional:
DDL (Data Definition Language) es un conjunto de comandos que se utilizan para definir la estructura de una base de datos, como crear o eliminar tablas, índices y vistas.
Algunos ejemplos de comandos DDL son:
- CREATE: para crear objetos en la base de datos, como tablas, índices o vistas.
- ALTER: para modificar la estructura de objetos existentes en la base de datos, como agregar o eliminar columnas de una tabla.
- TRUNCATE: para eliminar todos los datos de una tabla de manera rápida y eficiente.
- DROP: para eliminar objetos de la base de datos, como tablas o índices.
- DQL (Data Query Language) es un conjunto de comandos que se utilizan para recuperar datos de una base de datos, como seleccionar, insertar, actualizar y eliminar.
Algunos ejemplos de comandos DQL son:
- SELECT: para recuperar datos de una o varias tablas de la base de datos.
- INSERT: para agregar nuevas filas a una tabla.
- UPDATE: para modificar filas existentes en una tabla.
- DELETE: para eliminar filas de una tabla.
DML (Data Modification Language) es un conjunto de comandos que se utilizan para modificar los datos de una base de datos, como insertar, actualizar y eliminar.
Algunos ejemplos de comandos DML son:
- INSERT: para agregar nuevas filas a una tabla.
- UPDATE: para modificar filas existentes en una tabla.
- DELETE: para eliminar filas de una tabla.
DCL (Data Control Language) es un conjunto de comandos que se utilizan para controlar el acceso a los datos y a los objetos de una base de datos, como conceder o revocar permisos.
Algunos ejemplos de comandos DCL son:
- GRANT: para otorgar permisos a usuarios o roles para acceder a los objetos de la base de datos.
- REVOKE: para revocar permisos concedidos previamente a usuarios o roles.
TCL (Transaction Control Language) es un conjunto de comandos que se utilizan para controlar las transacciones en una base de datos, como confirmar o revertir cambios.
Algunos ejemplos de comandos TCL son:
- COMMIT: para confirmar los cambios realizados en una transacción.
- ROLLBACK: para revertir los cambios realizados en una transacción.
- SAVEPOINT: para establecer puntos de guardado durante una transacción para poder revertir solo parte de los cambios en caso de error.
A continuación, se presentan algunos ejemplos de uso de estos comandos en SQL Server:
Crear una tabla llamada «clientes» con dos columnas: «id» y «nombre»:
CREATE TABLE clientes (
id int PRIMARY KEY,
nombre varchar(255) NOT NULL
);
Insertar un nuevo cliente en la tabla «clientes»:
- INSERT INTO clientes (id, nombre) VALUES (1, ‘Juan Pérez’);
Actualizar el nombre de un cliente en la tabla «clientes»:
- UPDATE clientes SET nombre = ‘Juan Martínez’ WHERE id = 1;
Eliminar un cliente de la tabla «clientes»:
- DELETE FROM clientes WHERE id = 1;
Conceder permisos de lectura a un usuario sobre la tabla «clientes»:
- GRANT SELECT ON clientes TO user1;
Revertir los cambios realizados en una transacción:
- ROLLBACK TRANSACTION;
Una tabla en una base de datos es un conjunto de datos organizados en filas y columnas. Cada fila representa un registro, que es un conjunto de datos relacionados, como los datos de un empleado (nombre, edad, salario, etc.). Cada columna representa un campo, que es un tipo de dato particular (nombre, edad, salario, etc.). Las relaciones en una base de datos son la forma en que se relacionan distintas tablas entre sí. Por ejemplo, podríamos tener una tabla de empleados y una tabla de departamentos, y establecer una relación entre ellas para indicar que cada empleado pertenece a un departamento determinado.
Una clave primaria es un campo en una tabla que se utiliza para identificar de manera única a cada registro de la tabla. Por ejemplo, podríamos utilizar el número de empleado como clave primaria en la tabla de empleados.
Una clave foránea, por otro lado, es una clave que se utiliza para establecer una relación con otra tabla. Por ejemplo, podríamos utilizar la clave primaria de la tabla de departamentos como clave foránea en la tabla de empleados para indicar a qué departamento pertenece cada empleado.
Los índices en una base de datos son estructuras que se utilizan para mejorar la velocidad de las consultas. Por ejemplo, podríamos crear un índice en la tabla de empleados para mejorar la velocidad de las consultas que busquen empleados por nombre.
Los join en una base de datos son operaciones que se utilizan para combinar dos o más tablas en una sola consulta. Por ejemplo, podríamos utilizar un join para obtener una lista de empleados y sus departamentos respectivos. Existen diferentes tipos de join, como el inner join, que solo muestra los registros que cumplen con la condición de join, el left join, que muestra todos los registros de la tabla de la izquierda y solo los que cumplen la condición de la tabla de la derecha, y el right join, que muestra todos los registros de la tabla de la derecha y solo los que cumplen la condición de la tabla de la izquierda.
Por ejemplo, si quisiéramos obtener una lista de empleados y sus departamentos correspondientes, podríamos utilizar un join entre la tabla de empleados y la tabla de departamentos:
SELECT e.* , d.nombre_departamento FROM empleados e INNER JOIN departamentos d ON e.id_departamento = d.id_departamento
Las funciones lógicas en SQL nos permiten evaluar condiciones y devolver un valor verdadero o falso. Por ejemplo, podríamos utilizar la función «AND» para evaluar si dos condiciones son verdaderas al mismo tiempo. Las funciones de fecha nos permiten trabajar con campos de fecha y hora en la base de datos. Por ejemplo, podríamos utilizar la función «YEAR» para obtener solo el año de una fecha. Las funciones matemáticas nos permiten realizar operaciones matemáticas en los campos de nuestra base de datos. Por ejemplo, podríamos utilizar la función «SUM» para obtener la suma de un conjunto de números.
Algunos casos de uso de bases de datos en el desarrollo de software son:
- Almacenar y gestionar los datos necesarios para el funcionamiento de una aplicación web o móvil, como los datos de los usuarios, productos, compras, etc.
- Realizar análisis y obtener informes: a partir de los datos almacenados en la base de datos.
- Integrar la base de datos con otras aplicaciones o servicios para intercambiar datos.
- Sistemas de gestión empresarial: las bases de datos son esenciales en la mayoría de los sistemas de gestión empresarial, ya que nos permiten almacenar y gestionar información relacionada con clientes, proveedores, productos, ventas, compras y mucho más.
- Plataformas de e-commerce: las bases de datos son fundamentales en el funcionamiento de las plataformas de e-commerce, ya que nos permiten almacenar y gestionar información relacionada con productos, precios, inventario, pedidos y clientes.
- Aplicaciones de seguimiento de proyectos: las bases de datos nos permiten almacenar y gestionar información relacionada con tareas, plazos, responsables y avances en proyectos.
Algunos casos de uso de bases de datos en el análisis de datos son:
- Almacenar y procesar grandes cantidades de datos: para realizar análisis y obtener información valiosa para la toma de decisiones.
- Integrar diferentes fuentes de datos: para obtener una visión más completa y precisa.
- Realizar análisis predictivos: para hacer predicciones sobre el futuro.
- Son esenciales en el proceso de data mining, ya que nos permiten almacenar y procesar grandes cantidades de datos con el fin de descubrir patrones y tendencias que podrían ser útiles para tomar decisiones de negocio.
- Análisis de mercados: las bases de datos nos permiten almacenar y procesar datos sobre tendencias de mercado, preferencias de consumidores y comportamientos de compra, con el fin de obtener información valiosa para la toma de decisiones de negocio.
- Segmentación de clientes: las bases de datos nos permiten almacenar y procesar datos sobre nuestros clientes, como sus preferencias, hábitos de compra y perfiles demográficos, con el fin de segmentarlos y ofrecerles productos y servicios personalizados.
- Predicción de resultados: las bases de datos nos permiten almacenar y procesar datos sobre el rendimiento de nuestra empresa en el pasado, con el fin de utilizar técnicas de machine learning para predecir resultados futuros.
- Análisis de redes sociales: las bases de datos nos permiten almacenar y procesar datos recopilados de redes sociales, como publicaciones, interacciones y menciones, con el fin de obtener información valiosa sobre el sentimiento y la actividad de nuestra marca en las redes sociales.
Vamos a crear una Tabla llamada: Empleados:
CREATE TABLE empleados (
id int PRIMARY KEY,
nombre varchar(30) NOT NULL,
apellido varchar(30) NOT NULL,
cargo varchar(30) NOT NULL,
salario REAL NOT NULL
);
Por ejemplo, podríamos utilizar la función «INSERT» de SQL para crear un nuevo registro en la tabla de empleados. La sintaxis sería algo así:
INSERT INTO empleados (nombre, edad, salario)
VALUES (‘Juan’, 35, 45000);
Esto crearía un nuevo registro en la tabla de empleados con el nombre «Juan», la edad 35 y el salario 45000.
Para actualizar un registro existente, podríamos utilizar la función «UPDATE», de la siguiente manera:
UPDATE empleados
SET salario = 50000
WHERE nombre = ‘Juan’;
Esto actualizaría el salario del empleado con nombre «Juan» a 50000.
Para eliminar un registro, podríamos utilizar la función «DELETE»:
DELETE FROM empleados
WHERE nombre = ‘Juan’;
Esto eliminaría el registro del empleado con nombre «Juan» de la tabla de empleados.
La función «CASE» en SQL nos permite evaluar diferentes condiciones y devolver un valor diferente dependiendo del resultado.
Por ejemplo, podríamos utilizarla para asignar una categoría a los empleados según su salario:
SELECT nombre, salario,
CASE
WHEN salario < 30000 THEN ‘Bajo’
WHEN salario BETWEEN 30000 AND 50000 THEN ‘Medio’
ELSE ‘Alto’
END as categoria
FROM empleados;
Esta consulta devolvería el nombre y salario de los empleados, y una categoría dependiendo de si su salario es bajo, medio o alto.
La función «ORDER BY» nos permite ordenar los resultados de una consulta por uno o más campos. Por ejemplo, podríamos utilizarla para ordenar los empleados por nombre:
SELECT * FROM empleados
ORDER BY nombre;
La función «GROUP BY» nos permite agrupar los resultados de una consulta por uno o más campos. Por ejemplo, podríamos utilizarla para obtener el salario promedio de los empleados por departamento:
SELECT departamento, AVG(salario) as salario_promedio
FROM empleados
GROUP BY departamento;
La función «HAVING» nos permite filtrar los resultados de una consulta agrupada por una condición. Por ejemplo, podríamos utilizarla para obtener solo los departamentos que tienen un salario promedio mayor a 40000:
SELECT departamento, AVG(salario) as salario_promedio
FROM empleados
GROUP BY departamento
HAVING AVG(salario) > 40000;
La cláusula «IN» nos permite especificar una lista de valores que queremos que sean considerados en una consulta. Por ejemplo, podríamos utilizarla para obtener los empleados que pertenecen a los departamentos de informática o finanzas:
SELECT * FROM empleados
WHERE departamento IN (‘Informática’, ‘Finanzas’);
La cláusula «BETWEEN» nos permite especificar un rango de valores que queremos que sean considerados en una consulta. Por ejemplo, podríamos utilizarla para obtener los empleados que tienen un salario entre 30000 y 40000:
SELECT * FROM empleados
WHERE salario BETWEEN 30000 AND 40000;
Espero que esta información te haya sido útil y te haya ayudado a entender mejor el funcionamiento y las características de las bases de datos y del lenguaje SQL. Si tienes alguna pregunta o necesitas más detalles, no dudes en preguntar.